Analysing Open-Source Packages Sustainability using Machine Learning: Part-1: Introduction

In today’s fast-paced world, software evolves rapidly, making it essential to evaluate the maintenance of the dependencies we rely on.
Since new software dependencies emerge constantly, maintaining them is crucial, as outdated or poorly supported packages can introduce security risks and technical debt. To address this need, we developed the Package Sustainability Scanner (PSS), a tool that leverages machine learning to assess the sustainability of open-source packages.
Current challenges
The package managers offer labelling functionalities to indicate the state of software packages. However, these labels are often provided by the package authors, which can lead to discrepancies between the labeled state and the actual state. For instance, a package marked as "production/stable" on PyPI might not receive updates for an extended period, potentially resulting in future instability for projects relying on it.
In our initial research we compared the labels from the package manager to some basic filtering to bifurcate packages in healthy and unhealthy packages. As illustrated in the below charts, where the inner most circle is of labels from the package manager, the second circle is bifurcation based on last release date and outer most circle is bifurcation based on the basic filtering. This analysis revealed that the current labelling system is often inaccurate and not a reliable factor for making informed decisions about continuing to use a package.

Package distribution on PyPI

Package distribution on NPM
Our Approach
The ML model of the PSS tool classifies packages into four categories: Best, Good, Moderate, and Bad. The final model was developed using a structured two-phase approach, following the Machine Learning lifecycle. In the first phase, the model was trained exclusively for PyPI packages. The second phase extended its capabilities to classify both PyPI and NPM packages, enhancing its applicability across different ecosystems.
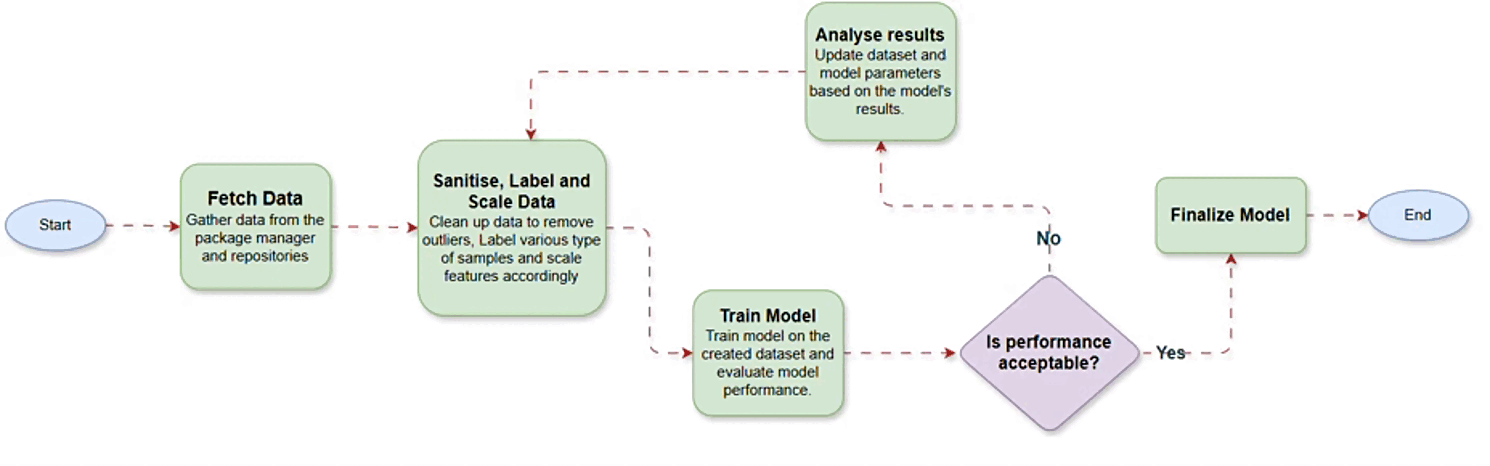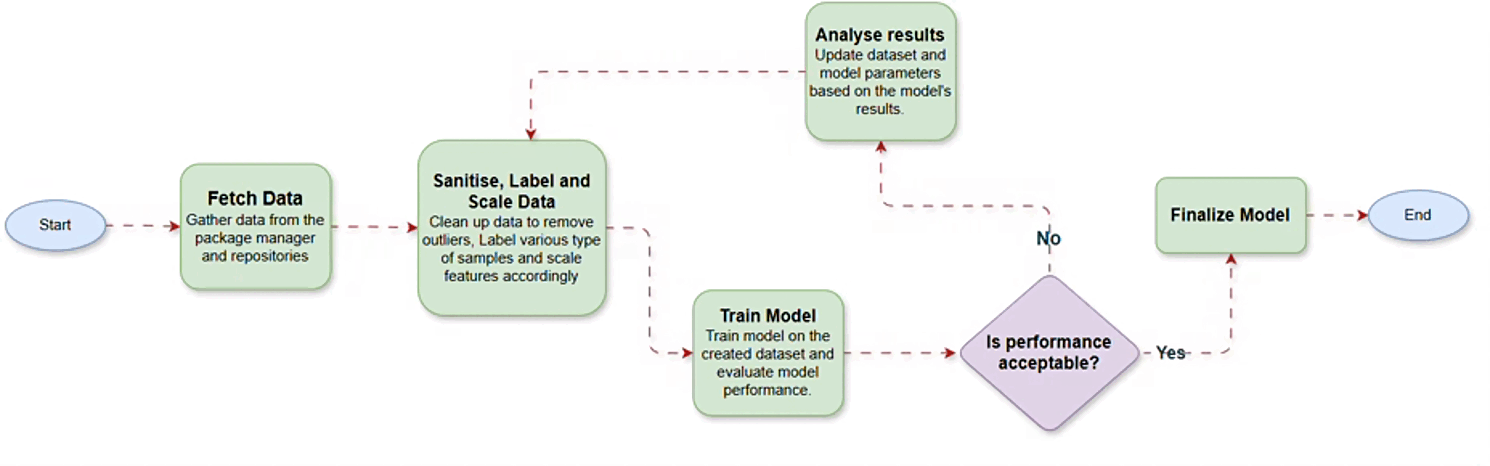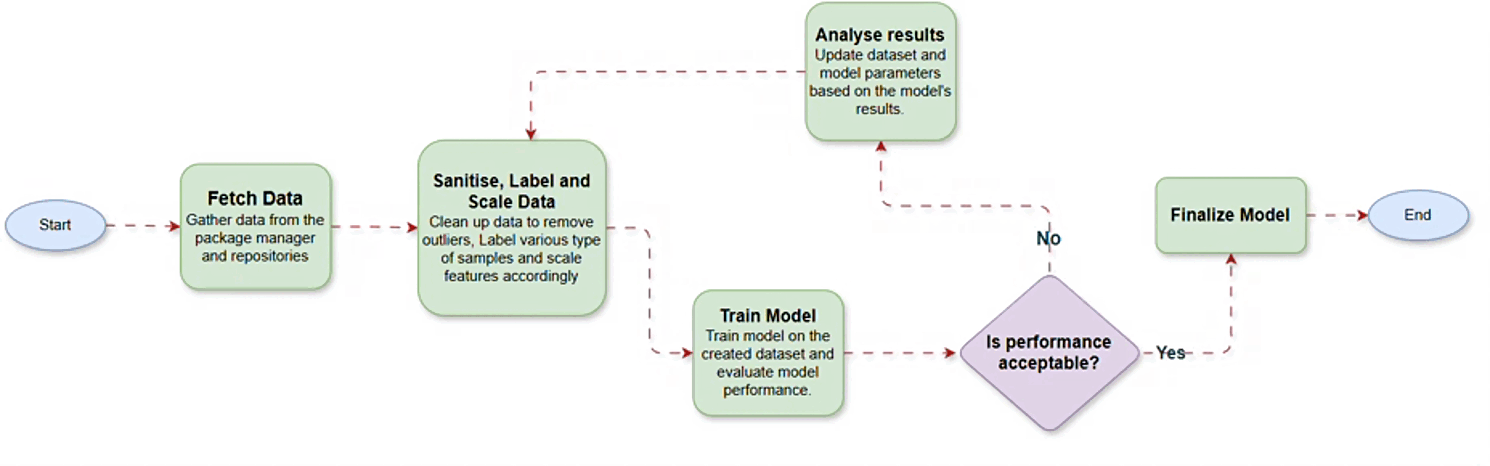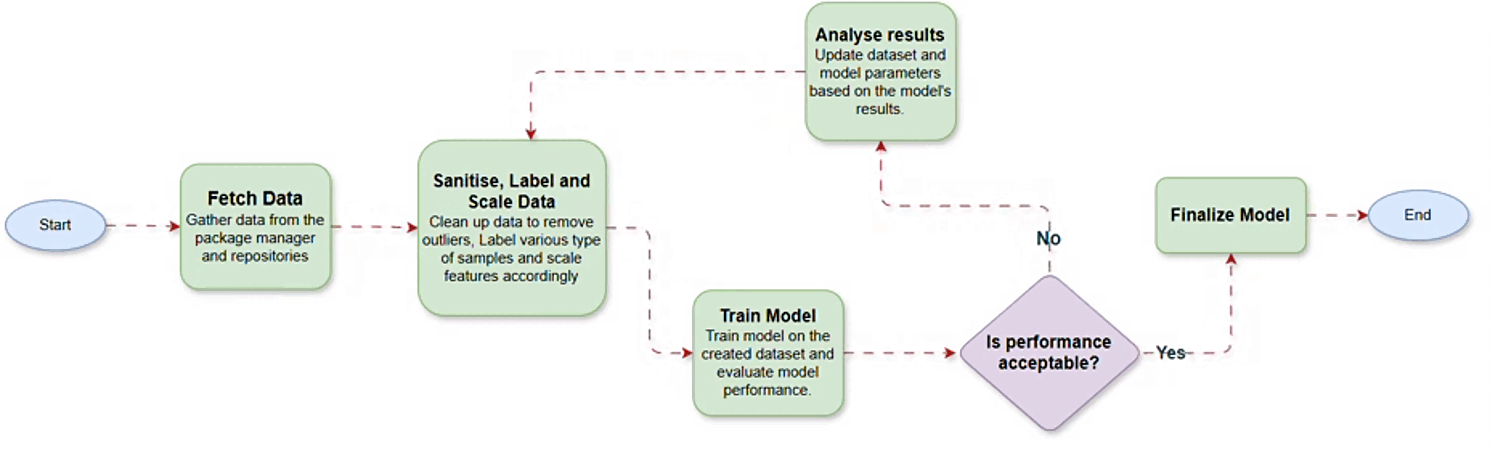
In the phase one, the primary challenge was gathering high-quality data to train the model. To address this, we sourced data from the PyPI repository API and corresponding repositories. Following data collection, we identified 12 key features including several synthetic ones to enhance the model’s interpretability.
After finalizing the features, we cleaned the data and applied necessary preprocessing steps, including feature scaling. Once the data was prepared, we experimented with multiple machine learning algorithms to identify the most promising candidates. This process helped us refine our focus to a select few algorithms, which were then optimized through parameter tuning. Further analysis revealed that incorporating additional features could improve the model’s performance. After updating the dataset and retraining the model with these new features, we achieved excellent results, successfully concluding phase one.
In phase two, we incorporated NPM packages by collecting data from the NPM package manager and related repositories. Our goal was to develop a unified model capable of evaluating packages from multiple ecosystems. To achieve this, we combined the PyPI and NPM datasets and trained the model on this consolidated data. The unified model performed exceptionally well across diverse data types and effectively handled edge cases.
Conclusion
The Package Sustainability Scanner (PSS) demonstrates strong potential in assessing the maintainability of open-source packages, achieving robust results for both PyPI and NPM. With continued refinement, it can become an indispensable tool for developers navigating the ever-evolving software ecosystem.
Stay tuned for the blog series where we deep dive into our journey.